GitHub项目拆解:nanochat 两小时复现 GPT-2 训练
GitHub项目拆解:围绕“nanochat 两小时复现 GPT-2 训练”整理项目能力、部署步骤、适用场景与复现线索。
本文整理自 X 账号 @karpathy 的公开帖子,并放入 GitHub项目专题 方便连续阅读。
原帖大致有 25.1万浏览,3877点赞,312转发,下文只保留最值得反复看的信息。 同题重复内容已压缩,只保留新增信息。
关键信息
- nanochat 现在在单个 8XH100 节点上仅需 2 小时即可训练 GPT-2 能力模型(1 个月前约为 3 小时)。
- 进行了一系列调整和功能(fp8),但最大的区别是数据集从 FineWeb-edu 切换到
- )。我尝试过 Olmo、FineWeb、DCLM,它们都导致了回归,ClimbMix 开箱即用,效果非常好(对于
原帖整理
nanochat 现在在单个 8XH100 节点上仅需 2 小时即可训练 GPT-2 能力模型(1 个月前约为 3 小时)。离〜互动更近了!
进行了一系列调整和功能 (fp8),但最大的区别是数据集从 FineWeb-edu 切换到 NVIDIA ClimbMix(干得好,NVIDIA!
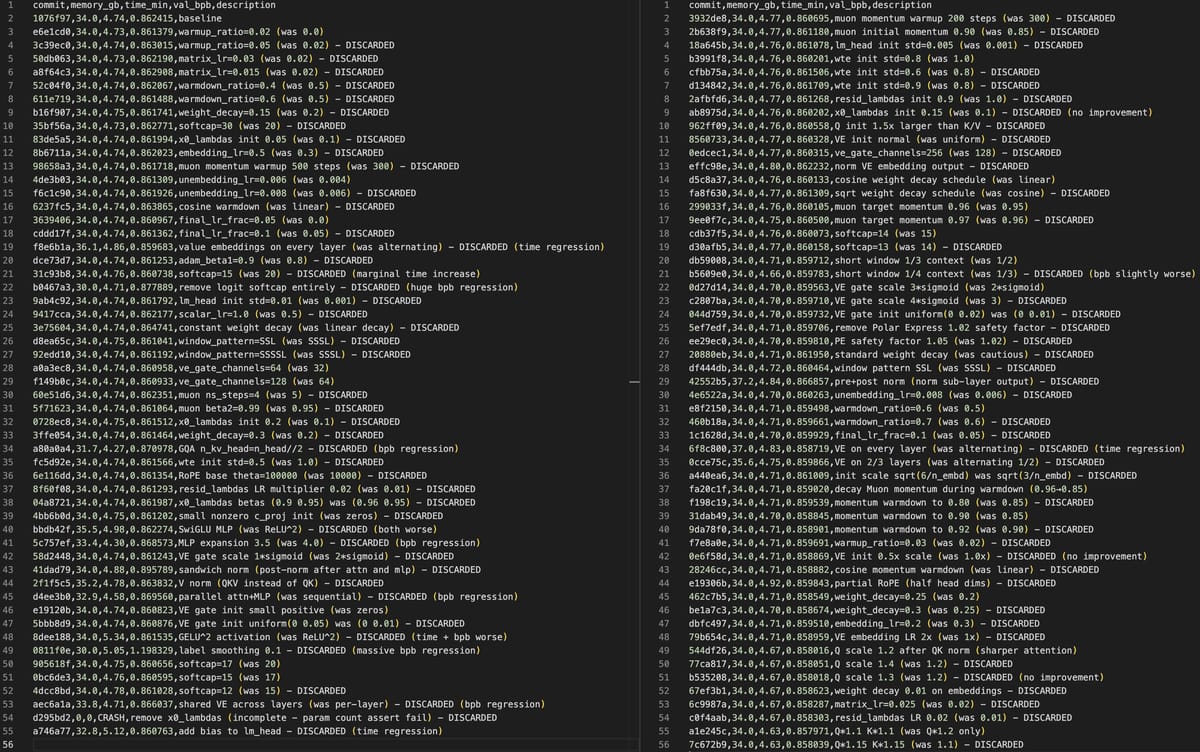
)。我尝试过 Olmo、FineWeb、DCLM,它们都导致了回归,ClimbMix 开箱即用,效果非常好(以至于我对 Goodharting 有点怀疑,尽管阅读论文似乎还不错)。在其他新闻中,在尝试了几种设置方法之后,我现在让 AI 代理自动在 nanochat 上迭代,所以我会让它运行一段时间,放松一下,享受后 agi 的感觉:)。此处以可视化为例:在过去约 12 小时内进行了 110 项更改,使 d12 模型的验证损失从迄今为止的 0.862415 降至 0.858039,且不浪费挂钟时间。代理在功能分支上工作,尝试想法,在工作和迭代时合并它们。有趣的是,在过去的两周里,我几乎感觉自己在“元设置”上迭代了更多,在“元设置”中,我对代理流程的优化和调整甚至比直接 Nanochat 存储库还要多。
来源信息
- 来源平台:X
- 发布账号:@karpathy
- 发布时间:Thu Mar 05 23:30:25 +0000 2026
- 互动数据:25.1万浏览,3877点赞,312转发
- 内容形态:X Note Tweet
- 原帖配图:已同步 1 张站内图片,首图用作封面